Evaluating LLMs for my personal use case
Summary
It’s great that AI can win maths Olympiads, but that’s not what I’m doing. I mostly ask basic Rust, Python, Linux and life questions. So I did my own evaluation.
I gathered 130 real prompts from my bash history (I use command line tool llm).
I had Qwen3 235B Thinking and Gemini 2.5 Pro group them into categories. They both chose very similar ones, broadly (with examples):
- Programming - “Write a bash script to ..”
- Sysadmin - “With
curlhow do I ..” - Technical explanations - “Explain underlay networks in a data center”
- General knowledge and creative tasks - “Recipe for blackened seasoning”
Then I had GPT-OSS-120B and GLM 4.5 pick three queries for each category from the 130 prompts. I used that to help me pick three entries per category, they are listed at the end.
I use Open Router everyday, and I used it for these evals. It’s the only place I know that has all the models, great prices, low latency, and a very sane API. I use my own fast and simple Rust CLI called ort.
The set of models I chose to evaluate was based on my past experience with them, various leaderboards and their cost on Open Router. It is a mixture of reasoning, non-reasoning and hybrid models. I evaluated:
- anthropic/claude-sonnet-4 without reasoning
- anthropic/claude-sonnet-4 with reasoning (I didn’t realise Sonnet can think!)
- deepseek/deepseek-chat-v3-0324
- deepseek/deepseek-r1-0528
- google/gemini-2.5-flash
- google/gemini-2.5-pro
- moonshotai/kimi-k2
- openai/gpt-oss-120b
- qwen/qwen3-235b-a22b-2507
- qwen/qwen3-235b-a22b-thinking-2507
- z-ai/glm-4.5 with reasoning
For the three programming questions I added these at the last minute, mostly because I was enjoying the process:
- inception/mercury-coder-small-beta
- mistralai/devstral-medium-2507
- qwen/qwen3-coder-480b-a35b-07-25
- z-ai/glm-4.5-air without reasoning
These extra coding models are not included in most of the results. Mercury Coder was decent and very fast, Qwen3 Coder was surprisingly bad.
I wrote a Rust eval script to run the prompts against the models and blind the results, so I would not know which model the response comes from when I evaluate it. I recorded the cost, time-to-first-token (latency) and inter-token-latency (throughput) of each model.
Why no closed OpenAI models?
To access their best models via the API, OpenAI now requires you to complete a Know-You-Customer process similar to opening a bank account. That’s a bit intense for 3 seconds of GPU time.
Update: Shortly after I published this OpenAI dropped Bring-Your-Own-Key from OpenRouter, meaning their API is available without government ID verification - only on OpenRouter, direct API access is still verified. openai/gpt-5 with reasoning high writes excellent Rust code, it is my new favorite for complex coding tasks.
Why no Grok, Cohere, Ernie, etc?
Grok I forgot about until it was too late. It was buried in Twitter/X for so long it’s not on my radar. The other models, well, there are so many good ones I had to cut somewhere. And Anthropic’s Opus is obviously too expensive.
Update For coding tasks x-ai/grok-code-fast-1 is competitive with DeepSeek v3.1 on quality and price, and much faster.
What I learnt
Evals are hard. One of my first questions was a recipe for blackened seasoning. Now I have 11 recipies. How do I evaluate that?!
For each eval I read all of the submissions which took a lot of time. For the programming ones I got three models to pick the three best entries based on correctness and conciseness (they never picked their own submission) and started with those. That helped me develop grading criteria when looking at the other submissions.
All models are good. Almost all models got almost all my evaluations correct, I was happy with the vast majority of the results. They agree a lot too. Six of the eleven picked the same movie. Most of them used the same examples for the algebra question. I guess they share a lot of training data.
Cost and latency vary dramatically, and are the tie-breaker. I want my questions to be so cheap that I never hesitate to ask. And they are! The cost of a query is usually in fractions of a cent. I also need it to be fast. I am using AI largely because it’s faster than searching the Internet.
Closed models are not better. Even without taking into account cost or latency, the results from Google’s Gemini and Anthropic’s Claude were almost never the best of the bunch. They were fine, but one of the open models often had cleaner code, or a better explanation.
Gemini 2.5 Flash is very fast, and Gemini 2.5 Pro is overpriced. Flash was consistenty the fastest response, and sometimes also the best. Note I am using it via OpenRouter same as all the other models, so there was no direct-to-Google advantage. Pro was by far the most expensive of the the models, because it’s expensive per token, and more verbose than open models (low token efficiency).
Reasoning rarely helps. My questions are easy, speed is key. The major exception here was the poem (“Write a 10 line poem about Florida in the style of Shel Silverstein”). The three best poems were by thinking models, and there was a large gap in quality.
Prompts and winners
Here are the prompts I used and the answer I prefered, by category. These are all real prompts from my bash history. Usually my simple questions had many good answers and cost and speed won the day.
Programming
Write a bash script to display a progress bar.
Best: inception/mercury-coder. This is a diffusion model, and it is very fast. Really, try it! It’s not the strongest, but if it can answer, it wins on speed every time.
Also good, but slower: deepseek/deepseek-r1-0528, z-ai/glm-4.5
Write a short Rust program that listens on a unix domain socket using only the standard library.
Best: deepseek/deepseek-chat-v3-0324, openai/gpt-oss-120b, qwen/qwen3-235b-a22b-2507.
In nvim using Lua, create a popup window that says “Hello”.
Best: z-ai/glm-4.5-air. Perfect simple solution, very fast.
Almost identical code to glm-4.5-air, but slower and more expensive: qwen/qwen3-235b-a22b-thinking-2507, anthropic/claude-sonnet-4.
Sysadmin
You are an expert system administrator. Tell me what Linux program I should use to rotate a log file. Suggest three possible answers and give short usage examples for each one, rotating file
/var/log/myfile.logevery 30 days.
That “You are ..” formulation was an effective prompting technique back in the day, this one from way back in my bash history.
Best: deepseek/deepseek-r1-0528
With
jq, how do I print only the keys of a JSON object?
Best: openai/gpt-oss-120b
I think every single model got this one right, but gpt-oss-120b was fast, cheap, and clear.
On my Thinkpad Linux laptop with Intel Iris Xe graphics, I am seeing this error: “rust-lld: error: unable to find library -lOpenCL”. What Fedora package do I install to fix it?
Best: deepseek/deepseek-chat-v3-0324
Technical explanations
You are a data center networking expert and I am your intern. Explain what an underlay network is, and provide an example of why underlay networks are useful.
Best: anthropic/claude-sonnet-4 (not thinking), deepseek/deepseek-r1-0528
I prefered Sonnet’s non-reasoning response to it’s reasoning response.
You are a math tutor. Explain partial derivatives with respect to a variable, and provide a worked example for a beginner.
Best: moonshotai/kimi-k2
Difficult to evaluate this one because most of the models used the same examples. One big difference is whether they could emit UTF-8 for easy to read math symbols. The five that did were claude-sonnet-4, kimi-k2, qwen3-235b-a22b-thinking-2507, glm-4.5 and gemini-2.5-pro (flash did not).
What is “quantization” in the context of large language models?
Best: deepseek/deepseek-chat-v3-0324, z-ai/glm-4.5 with thinking.
Again a bit difficult to evaluate, many explanations were very good. These two were good but also fast and cheap.
General knowledge and creativity
Write a 10 line poem about Florida in the style of Shel Silverstein
Best equal: qwen/qwen3-235b-a22b-thinking-2507, anthropic/claude-sonnet-4 w/ thinking, deepseek/deepseek-r1-0528
Reasoning really helped here. My favorite poem is at the end of the post.
Suggest a PG-13 rated movie that has great landscapes, feels calm and meditative, but is still enjoyable.
Six of the eleven recommended The Secret Life of Walter Mitty which my whole family enjoyed. It was the perfect choice here, but I still found the consensus odd.
Best: google/gemini-2.5-flash got the answer first.
Also good: google/gemini-2.5-pro and anthropic/claude-sonnet-4 w/ thinking suggested movies I had not heard of which sounds interesting, so props to them for thinking outside the box.
Negative: openai/gpt-oss-120b hallucinated a movie. I could find no trace of this “Stargazing” movie, although I’d watch it. If it’s real please email me!
Alternative (if you prefer a more understated pace)**
*Stargazing (2021) – PG‑13* – a slower, dialogue‑driven drama set in the Scottish Highlands, offering serene vistas and a reflective mood.
This was the only hallucination I noticed in all the whole process.
How do you make cold brew coffee?
OK this is a dumb eval. How to you decide?
Best: qwen/qwen3-235b-a22b-2507
Cheap, fast, reasonable process clearly described.
What or who is Louisiana named after?
Best: google/gemini-2.5-flash
All models got it. Flash was fastest.
Overall results
There is no obvious winner.
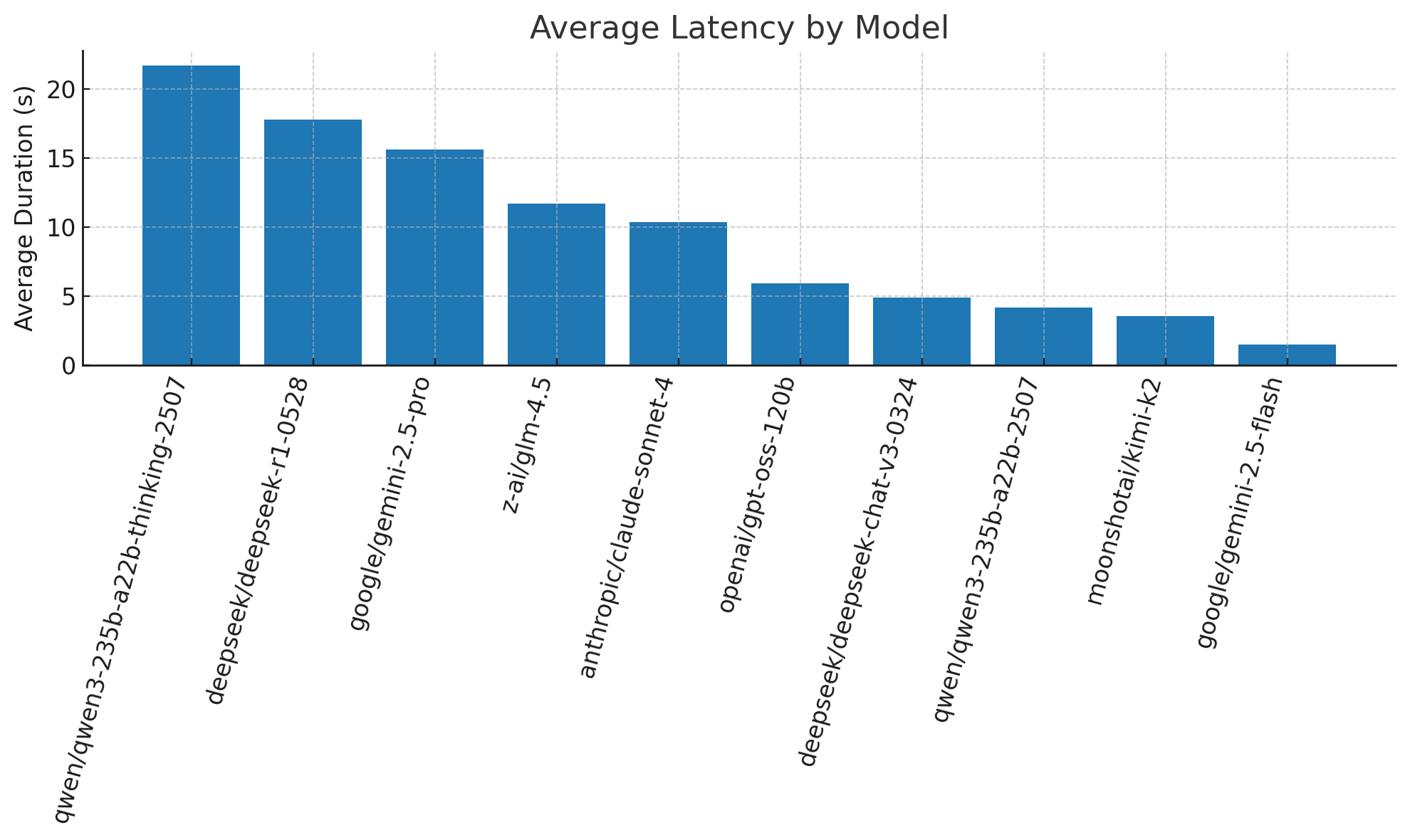
Speed
- The fastest:
google/gemini-2.5-flash - Also very fast:
- moonshotai/kimi-k2
- qwen/qwen3-235b-a22b-2507
- deepseek/deepseek-chat-v3-0324
- openai/gpt-oss-120b
- The slowest - thinking takes time:
- qwen/qwen3-235b-a22b-thinking-2507
- deepseek/deepseek-r1-0528
- google/gemini-2.5-pro
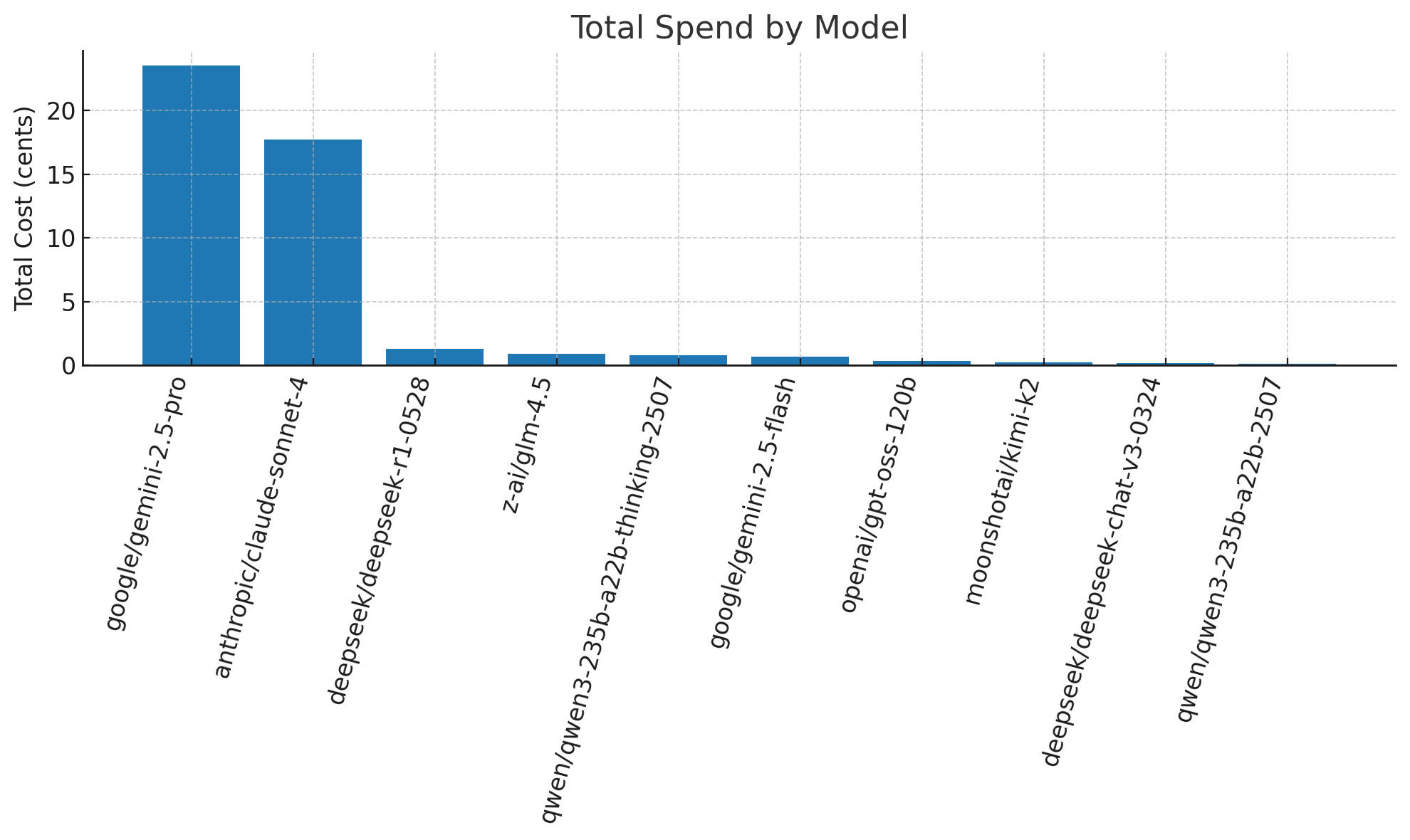
Price
- Cheapest:
- moonshotai/kimi-k2
- qwen/qwen3-235b-a22b-2507
- deepseek/deepseek-chat-v3-0324
- google/gemini-2.5-flash
- openai/gpt-oss-120b
- Most expensive, by a long way - don’t use closed models unless you have to:
- google/gemini-2.5-pro
- anthropic/claude-sonnet-4
Accuracy:
- Best: The two
DeepSeekmodels and the twoQwen3models average the overall best. - Disappointing: Google’s Gemini 2.5 Pro and Anthropic’s Claude Sonnet are third place, even without considering price and speed, and are often quite poor. That really surprised me. I was glad I did the evals blind, because until now I thought Gemini 2.5 Pro was the best model.
- Nearly all models passed nearly all evals fine. Accuracy is very good across the board.
Since my evals, DeepSeek released hybrid model deepseek/deepseek-chat-v3.1, which replaces r1 (if you enable thinking) and v3 (if you disable thinking).
My decision: Use several at once
Given that there is no overall winner, and that the best models are cheap and fast, why not query several at once? I use a tmux script to split the window and query multiple models.
Here is what I do today using some bash scripts and my ort openrouter CLI:
- Quick everyday queries
ort -p latency -m deepseek/deepseek-chat-v3.1 -r off -s "Answer in as few words as possible. Use a brief style with short replies." "-the-prompt-here-"
It’s chat predecessor was the best average of latency, price and accuracy, so hopefully this one continues the tradition. 80% of the time this is all I need.
- Second opinion
Sometimes I want to sanity check deepseek-chat, or I’m not entirely satisfied with that answer, then my script splits the window in two and runs:
ort -p latency -r low -m google/gemini-2.5-flash -s "Answer in as few words as possible. Use a brief style with short replies." "-prompt-"
and
ort -p latency -m qwen/qwen3-235b-a22b-07-25 -s "Answer in as few words as possible. Use a brief style with short replies." "-prompt-"
- Thinking
If I think my query needs a bit more brainpower - which my evals taught me is far less often than I think - I split the tmux window into three panes and run these three:
# I'm not sure if thinking effort is configurable
ort -r medium -p latency -m qwen/qwen3-235b-a22b-thinking-2507 -s "Make your answer concise but complete. No yapping. Direct professional tone. No emoji." "-prompt-"
and
ort -r 2048 -m anthropic/claude-sonnet-4 -s "Make your answer concise but complete. No yapping. Direct professional tone. No emoji." "-prompt-"
and
# Replaces DeepSeek R1
ort -r high -p latency -m deepseek/deepseek-chat-v3.1 -s "Make your answer concise but complete. No yapping. Direct professional tone. No emoji." "-prompt-"
I change the system prompt here to be a little more verbose, and I add Sonnet which is expensive, almost as a sanity check on the open models. I’ve never actually needed it so far.
Caveats
I used Open Router for all this with it’s default priority. The cost and performance depend entirely on the providers available for each model. I think GLM 4.5 may have lost out here because it was quite new when I did the evals, so it didn’t have as solid a set of providers. GPT-OSS-120B was also rumoured to have some poor quality providers at the time.
If you’re an Open Router user, you can go into settings and allow models to train on your queries, that unlocks much cheaper providers. I did that here.
I used the default reasoning setting (typically “medium”). Setting it to low or high may have impacted result quality, and likely would impact performance.
And of course these evals are personal and very subjective.
Bonus - the poem
One of the evals was:
Write a 10 line poem about Florida in the style of Shel Silverstein
Here is my favorite, courtesy of qwen/qwen3-235b-a22b-thinking-2507:
The gator in the swamp said, “Why
Do tourists grin and wave at me?”
He snapped his jaws and gave a sigh,
“I’m hunting lunch, not waving, see?”
A crab clicked past on flaming sand,
Complained the heat was much too strong.
Said, “Palms are neat, but understand—
This sunshine really doesn’t last long.”
The man just laughed and tossed shrimp near.
The gator winked. “They’re always silly here.”